Passing Code Across AI Platforms
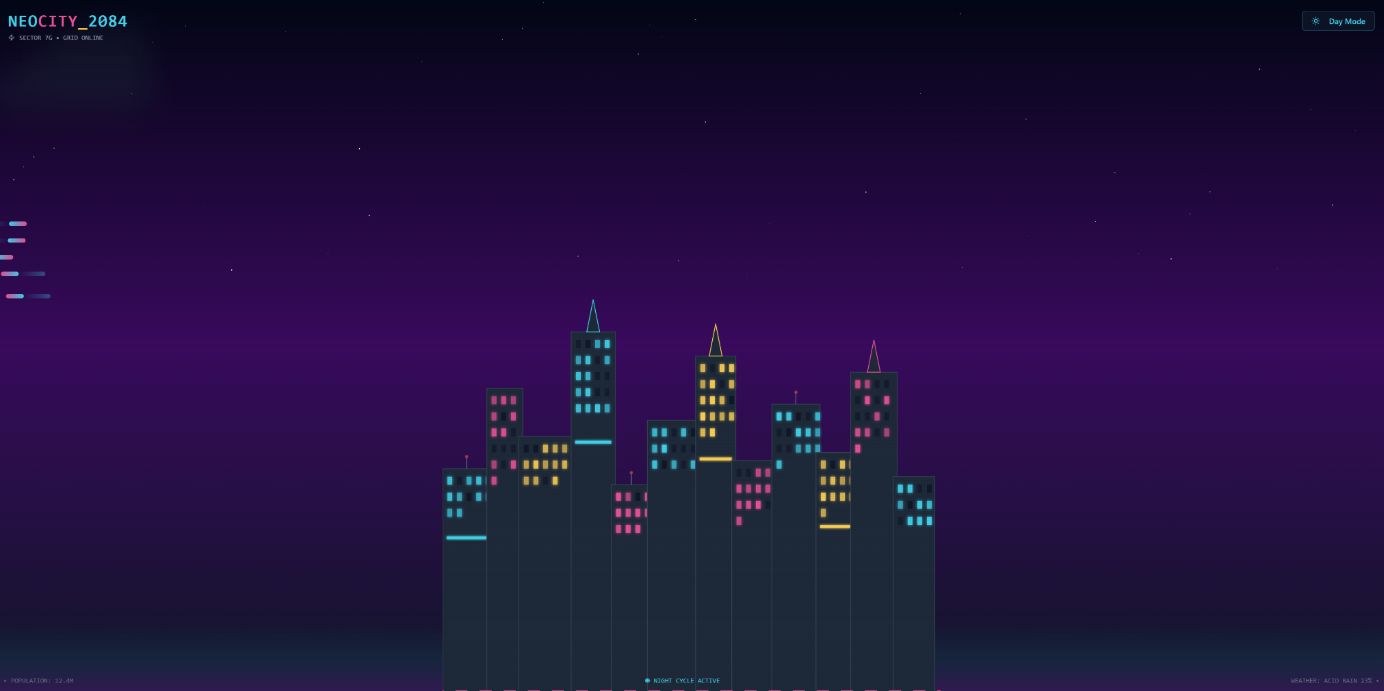
The above artifact is the result of iterative relay between PDCo Dev Studio and Gemini Pro (Canvas). All other embedded examples in this article represent first-pass outputs only.
I. The Myth of the “Best Model”
In early 2026, AI evaluation discourse remains dominated by leaderboards. Models are compared by benchmark deltas, reasoning tests, token limits, and synthetic coding suites. The implicit assumption is that performance is scalar: one model is simply better.
But generative product work does not resemble a benchmark.
Benchmarks reward deterministic correctness under controlled constraints. Product generation rewards coherence under ambiguity. Benchmarks evaluate answer quality. Product generation exposes architectural philosophy.
These are not the same task.
Human–AI co-creation research has already demonstrated that output quality in creative and engineering domains depends heavily on interaction structure rather than raw model capability.^[1] Iterative framing, constraint reinforcement, and staged refinement consistently outperform single-shot prompting.^[2] Yet most public comparisons still treat LLMs as independent competitors rather than composable components.
This article rejects that framing.
Instead of asking which model is “best,” we ask:
Which models are worth using, and in what sequence?
II. Experiment Design
To ground the analysis, we ran a controlled generative test across platforms.
Prompt (identical across models):
“Generate a pixel-based animation of a futuristic cityscape.”
Constraints:
- Must output complete HTML/CSS/JS.
- Must run in a single iframe.
- No post-editing.
- No cross-model modification.
- No manual structural correction.
Each model was evaluated on its first-pass output.
The relay artifact shown at the top of this article is intentionally excluded from baseline scoring. It represents iterative passing between PDCo Dev Studio and Gemini. Its purpose is diagnostic: to show what emerges when models are sequenced rather than isolated.
This distinction matters.
Studies of LLM interaction stability show that iterative refinement often introduces drift, architectural mutation, and feature regression when state continuity is not preserved.^[3] Evaluating baseline output separately from relay behavior allows us to measure both generative competence and structural resilience.
Evaluation Axes
Each model is evaluated across the following dimensions:
- Baseline Visual Quality
- Code Architecture Coherence
- Determinism / Stability
- Feature Preservation Under Iteration
- Context Continuity
- Debuggability
- Packaging / Deployment Friction
- Relay Utility
- Overall Workflow Value
Scores are reported to two decimal places. A rating above 9.00 indicates production-caliber reliability. Scores between 7.50 and 8.99 indicate strong but constrained utility. Anything below 6.00 suggests fragility under real-world conditions.
The objective is not aesthetic preference. It is production viability.
III. Baseline Outputs — First-Pass Only
The following sections present each model’s first response to the identical prompt. No edits. No relay. No improvement passes.
This isolates default generative character.
1. PDCo Dev Studio (GPT-4o-mini API)
Baseline output characteristics:
- Single-file architecture.
- Clean procedural generation logic.
- Moderate starfield + skyline composition.
- Minimal UI scaffolding.
- Simple neon gradient aesthetic.
Strengths:
- Structural clarity.
- Low deployment friction.
- Easy to modify.
- Deterministic enough for iteration.
Weaknesses:
- Limited visual layering.
- No parallax.
- No seeded determinism.
- Window flicker logic introduces stochastic inconsistency.
The model clearly optimizes for interpretability and constraint alignment. It produces stable, comprehensible systems but does not aggressively push visual complexity.
Baseline Assessment: Competent, clean, conservative.
2. Gemini Pro (Canvas)
Baseline output characteristics:
- Higher visual density.
- Multi-layer parallax.
- Palette cycling.
- User interaction (click-to-change theme).
- Atmospheric fog and traffic simulation.
Strengths:
- Strong visual imagination.
- Layered scene construction.
- More ambitious animation logic.
- Cohesive aesthetic system.
Weaknesses:
- Tendency toward structural mutation under iteration.
- Occasional redefinition of internal heuristics.
- Increased debugging surface area.
Gemini optimizes for visual expressiveness and layered complexity. It behaves more like a graphics designer than a systems engineer.
Baseline Assessment: High aesthetic output; moderate structural volatility.
3. ChatGPT 5.2 Thinking (Canvas)
Baseline output characteristics:
- Logical low-resolution buffer scaling.
- Deterministic seeded generation.
- UI sliders controlling rain, traffic, hue, neon.
- Modular rendering pipeline.
Strengths:
- Explicit architectural segmentation.
- Adjustable parameters.
- Reproducible scene state.
- Advanced layering logic.
Weaknesses:
- Increased complexity footprint.
- Higher cognitive load for modification.
- More code than minimal use-cases require.
This output suggests optimization for extensibility rather than minimalism. It reads as a production-ready scaffold rather than a quick generative artifact.
Baseline Assessment: Architecturally mature; slightly heavy for simple tasks.
4. Claude Code (Sonnet 4.5)
Baseline output characteristics:
- Pixel-drawing via nested loops.
- Billboard animation.
- Simple flying vehicle logic.
- Structured but traditional approach.
Strengths:
- Clear rendering primitives.
- Predictable flow.
- Easy conceptual understanding.
Weaknesses:
- Repeated randomization inside draw loops.
- Flicker logic tied to frame randomness.
- Limited abstraction.
Claude demonstrates consistent compositional logic but exhibits lower emphasis on architectural refinement compared to higher-tier models.
Baseline Assessment: Solid mid-tier generative coder.
5. Grok 4.1 (Code Mode)
Baseline output characteristics:
- Explicit low-resolution scaling.
- Structured vehicle and window systems.
- Deterministic flicker probability.
- Clean loop architecture.
Strengths:
- Clear separation of update vs render.
- Simple deployment.
- Strong pixel-art discipline.
Weaknesses:
- Limited atmospheric layering.
- Lower creative risk.
- Less dynamic aesthetic variation.
Grok behaves conservatively but predictably.
Baseline Assessment: Reliable baseline generator; moderate creative ceiling.
6. LlamaCode GLM 4.6
Baseline behavior:
- Multi-file structure by default.
- Complex project scaffolding.
- Partial runtime inconsistencies.
- Slower generation cycle.
Strengths:
- Ambition toward full project architecture.
- Clear separation of concerns.
Weaknesses:
- Not iframe-friendly by default.
- Execution friction.
- Inconsistent runtime results.
Baseline Assessment: Architecturally over-scoped for the task; not deployment-ready in single-pass form.
7. Base 44
Observed behavior:
- Limited code transparency.
- Subpar visual output.
- Restricted structural visibility.
Strengths:
- Rapid generation.
Weaknesses:
- Low output quality.
- Poor inspectability.
- Low modification affordance.
Baseline Assessment: Not production-viable for this class of task.
IV. Relay Case Study — PDCo Dev Studio ↔ Gemini
The artifact at the top of this article did not emerge from a single model.
It emerged from a relay.
Initial state: PDCo Dev Studio generated a structurally clean but visually restrained skyline. The architecture was legible, editable, and minimal. No parallax layers. No seeded determinism. No depth sorting.
Second phase: Gemini ingested that structure and amplified it. It introduced:
- Multi-layer parallax systems
- Dynamic sky gradients
- Shooting stars and flying vehicles
- CRT scanline overlays
- Atmospheric vignette
- Palette sophistication
The scene transformed from procedural toy to aesthetic system.
But something else happened.
Gemini reinterpreted portions of the architectural logic. It replaced certain simplifications with new heuristics. In some iterations, it silently modified structural assumptions—such as pixel resolution scaling or object regeneration behavior. In a purely single-model workflow, this would read as drift. In relay mode, it becomes a design negotiation.
This interaction pattern aligns with known behavior in extended LLM refinement loops, where iterative updates may introduce unintended architectural mutation when model priors override prior constraints.^[3] Feature regression under refinement is a documented phenomenon in code-generation studies, particularly when context boundaries blur between instruction and implementation state.^[4]
Relay exposes this tension.
PDCo Dev Studio contributed:
- Intent fidelity
- Structural continuity
- Conservative modification behavior
- Constraint adherence
Gemini contributed:
- Visual ambition
- Layering sophistication
- Animation richness
- Environmental coherence
The relay artifact is therefore diagnostic. It demonstrates that neither system alone produced the final quality level. It also demonstrates that neither system alone preserved both clarity and ambition simultaneously.
Relay Elasticity
We define Relay Elasticity as:
The capacity of a model to meaningfully improve an artifact without collapsing its existing structure.
PDCo Dev Studio shows high structural preservation but moderate creative amplification.
Gemini shows high creative amplification but moderate structural preservation.
When sequenced carefully, they compensate for each other’s bias.
This is not a coincidence. Research in human–AI co-creative systems suggests that complementary bias pairing often outperforms single-agent optimization in creative domains.^[5]
Relay is not redundancy. It is specialization.
V. Evaluation Matrix
Scoring Framework
Scores are assigned from 0.00 to 10.00 across nine axes:
- Baseline Visual Quality
- Code Architecture Coherence
- Determinism / Stability
- Feature Preservation Under Iteration
- Context Continuity
- Debuggability
- Packaging / Deployment Friction
- Relay Utility
- Overall Workflow Value
Below is the comparative matrix.
| Model | Visual | Architecture | Stability | Feature Preservation | Context | Debuggability | Packaging | Relay Utility | Overall |
|---|---|---|---|---|---|---|---|---|---|
| PDCo Dev Studio | 7.10 | 8.40 | 8.20 | 8.00 | 8.60 | 8.50 | 9.00 | 8.70 | 8.28 |
| Gemini Pro (Canvas) | 9.10 | 7.80 | 6.80 | 6.70 | 6.90 | 7.20 | 7.10 | 8.90 | 7.94 |
| ChatGPT 5.2 Thinking | 8.70 | 9.20 | 8.80 | 8.60 | 8.70 | 8.90 | 8.20 | 8.40 | 8.72 |
| Claude Code (Sonnet 4.5) | 7.20 | 7.50 | 7.10 | 6.90 | 7.20 | 7.80 | 8.00 | 7.10 | 7.20 |
| Grok 4.1 (Code Mode) | 7.40 | 7.80 | 7.90 | 7.30 | 7.50 | 7.60 | 8.10 | 7.30 | 7.63 |
| LlamaCode GLM 4.6 | 5.90 | 7.10 | 5.80 | 5.20 | 6.00 | 6.30 | 4.50 | 5.10 | 5.76 |
| Base 44 | 4.80 | 5.10 | 5.40 | 4.20 | 4.90 | 4.60 | 5.00 | 4.30 | 4.76 |
Interpretation
Highest Baseline Architecture: ChatGPT 5.2 Thinking
Highest Baseline Visual: Gemini
Highest Packaging Simplicity: PDCo Dev Studio
Highest Relay Utility: Gemini (when paired intentionally)
The model with the strongest overall workflow value is ChatGPT 5.2 Thinking due to architectural maturity and deterministic scaffolding.
However, no model dominates across all axes.
VI. Tier Classification
Tier A — Worth Using
- ChatGPT 5.2 Thinking
- PDCo Dev Studio
- Gemini (with relay oversight)
These models are capable of production-caliber output when used appropriately.
Tier B — Situational
- Claude Code
- Grok 4.1
Useful for constrained tasks or simpler artifacts.
Tier C — Not Production-Grade
- LlamaCode GLM 4.6 (for single-file deployment tasks)
- Base 44
Architecturally inconsistent or deployment-friction-heavy for this use case.
VII. What This Reveals
The deeper lesson is not about rankings.
It is about bias.
Each model encodes a design philosophy:
- Some optimize for compliance.
- Some optimize for aesthetic density.
- Some optimize for structural explicitness.
- Some optimize for generative flair.
The production mistake is expecting any one of them to optimize for all simultaneously.
Generative AI today behaves less like a single brain and more like a cabinet of specialized advisors. The builder’s advantage comes from sequencing them intelligently.
VIII. Conclusion — AI as Modular Cognitive Infrastructure
The relay artifact at the top of this article is not an accident. It is a pattern.
PDCo Dev Studio establishes structural intent.
Gemini amplifies visual ambition.
ChatGPT 5.2 scaffolds extensibility.
When used deliberately, the composite exceeds any isolated baseline.
The future of generative product development will not be model maximalism. It will be orchestration.
For those experimenting with multi-model relay workflows, the simplest environment to prototype structured iteration remains a constrained single-file deployment context such as dev.primarydesignco.com, where architectural mutation is easier to detect and correct before complexity compounds.
The question is no longer:
Which model is best?
It is:
Which sequence produces the strongest artifact?
References
^[1]: Bansal, G., et al. (2021). “Does the Whole Exceed Its Parts? The Effect of AI Explanations on Complementary Team Performance.” CHI Conference on Human Factors in Computing Systems.
^[2]: Wu, T., et al. (2022). “Iterative Prompting for Improved Code Generation.” arXiv preprint arXiv:2207.10397.
^[3]: Zamfirescu-Pereira, J., et al. (2023). “Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts.” CHI 2023.
^[4]: Chen, M., et al. (2021). “Evaluating Large Language Models Trained on Code.” arXiv:2107.03374.
^[5]: Kambhampati, S. (2023). “Challenges of Human–AI Complementarity.” Communications of the ACM.